在 Core Data 中进行并发编程可能并不困难,但是充满了陷阱。即使对 Core Data 有充分的经验,稍有疏忽也可能在代码中埋下隐患,从而使应用程序变得不安全。SwiftData 作为 Core Data 的继任者,提供了一种更加优雅、更加安全的并发编程机制。本文将介绍 SwiftData 是如何解决这些问题的,并为开发者提供更好的并发编程体验。
本文的内容中将涉及 Swift 中的 async/await、Task、Actor 等并发处理功能。读者需要具备一定的 Swift 并发编程经验。
用串行队列来避免数据竞争
我们经常说,Core Data 中的托管对象实例(NSManagedObject)和托管对象上下文(NSManagedObjectContext)不是线程安全的。那么,为什么会出现不安全的问题?Core Data 解决这个问题的方式又是什么呢?
其实,主要的不安全点就出在数据竞争上(在多线程环境中同时对同一个数据进行修改操作)。Core Data 通过在串行队列中对托管对象实例和托管对象上下文实例进行操作,从而避免数据竞争问题。这也是为什么我们需要将操作代码放置在 perform 或 performAndWait 的闭包中。
对于视图上下文(viewContext)和其中注册的托管对象实例,开发者应该在主线程队列中进行操作。同样,对于私有上下文和其中注册的托管对象,我们应该在私有上下文所创建的串行队列中进行操作。perform 方法将保证所有的操作都在正确的队列中进行。
阅读 关于 Core Data 并发编程的几点提示 一文,详细了解不同类型的托管对象上下文、串行队列、
perform的使用方法以及其他在 Core Data 中进行并发编程的注意事项。
从理论上讲,只要我们严格按照上述要求进行编程,就可以在 Core Data 中避免大多数并发问题。因此,开发者经常会编写类似以下的代码:
func updateItem(_ item: Item, timestamp: Date?) async throws {
guard let context = item.managedObjectContext else { throw MyError.noContext }
try await context.perform {
item.timestamp = timestamp
try context.save()
}
}当代码中存在大量的 perform 方法时,会降低代码的可读性。这也是许多开发者所抱怨的问题。
如何创建使用私有队列的 ModelContext
在 Core Data 中,开发者可以使用一种十分明确的方式来创建不同类型的托管对象上下文:
// view context - main queue concurrency type
let viewContext = container.viewContext
let mainContext = NSManagedObjectContext(concurrencyType: .mainQueueConcurrencyType)
// private context - private queue concurrency type
let privateContext = container.newBackgroundContext()
let privateContext = NSManagedObjectContext(concurrencyType: .privateQueueConcurrencyType)甚至可以在私有上下文中直接进行操作,而无需显式创建。
container.performBackgroundTask{ context in
...
}然而,SwiftData 对 ModelContext( NSManagedObjectContext 的包装版本 )的创建逻辑进行了调整。新创建的上下文的类型取决于其所处的队列。换句话说,在主线程上创建的 ModelContext 将自动使用主线程队列( com. apple. main-thread ),而在其他线程( 非主线程 )上创建的 ModelContext 将使用私有队列。
Task.detached {
let privateContext = ModelContext(container)
}特别需要注意的是,当通过 Task. init 创建一个新的任务时,它会继承创建它的父任务或 Actor 的执行上下文。这意味着,通过下面的代码,并不能创建出使用私有队列的 ModelContext:
// In SwiftUI View
Button("Create New Context"){
let container = modelContext.container
Task{
// Using main queue, not background context
let privateContext = ModelContext(container)
}
}
SomeView()
.task {
// Using main queue, not background context
let privateContext = ModelContext(modelContext.container)
}这是因为在 SwiftUI 中,视图的 body 被标注为 @MainActor ,因此建议使用 Task.detached 来确保在非主线程上创建使用私有队列的 ModelContext。
在主线程上创建的 ModelContext 是一个独立的实例,与 ModelContainer 实例的 mainContext 属性提供的上下文实例并不相同。尽管它们都在主队列上进行操作,但它们分别管理着独立的注册对象。
Actor:串行队列更优雅的实现
从 5.5 版本开始,Swift 引入了 Actor 的概念。与串行队列一样,它们可以用于解决数据竞争问题,并确保数据的一致性。与通过 perform 方法运行在特定串行队列上的方式相比,Actor 提供了一种更高级和更优雅的实现方式。
每个 Actor 都有一个关联的串行队列,用于执行其方法和任务。这个队列基于 GCD,由 GCD 负责底层线程管理和任务调度。这样可以确保 Actor 的方法和任务以串行方式执行,即同一时间只能有一个任务在执行。这保证了 Actor 内部的状态和数据在任何时候都是线程安全的,避免了并发访问的问题。
尽管从理论上来说,可以使用 Actor 来限制代码对托管对象上下文和托管对象的操作,但由于之前的 Swift 版本并没有提供自定义 Actor 执行者(Executor)的能力,这种方式并没有被采用。好在,Swift 5.9 版本弥补了之前的遗憾,让 SwiftData 通过 Actor 提供了更加优雅的并发编程体验。
Custom Actor Executors: 该提案介绍了一种自定义 Swift Actor 执行器的基本机制。通过提供执行器的实例,Actor 可以影响它们运行任务的执行位置,同时保持 Actor 模型所保证的互斥性和隔离性。
得益于 Swift 的新功能 “宏”,在 SwiftData 中,创建一个对应特定串行队列的 Actor 十分容易:
@ModelActor
actor DataHandler {}通过为该 Actor 添加更多数据操作逻辑代码,开发者可以安全地使用该 Actor 实例来操作数据。
extension DataHandler {
func updateItem(_ item: Item, timestamp: Date) throws {
item.timestamp = timestamp
try modelContext.save()
}
func newItem(timestamp: Date) throws -> Item {
let item = Item(timestamp: timestamp)
modelContext.insert(item)
try modelContext.save()
return item
}
}你可以使用以下方式调用上述代码:
let handler = DataHandler(modelContainer: container)
let item = try await handler.newItem(timestamp: .now)之后,无论在哪个线程中调用 DataHandler 的方法,这些操作都将在一个特定的串行队列中进行。开发者再也不用为编写大量包含 perform 的代码而苦恼了。
还记得上一节讨论的创建 ModelContext 应注意的事项吗?在创建一个通过 ModelActor 宏构建的实例时,所采用的规则也是一样的。新创建的 Actor 实例所采用的串行队列类型取决于创建它的线程。
Task.detached {
// Using private queue
let handler = DataHandler(modelContainer: container)
let item = try await handler.newItem(timestamp: .now)
}ModelActor 宏的秘密
ModelActor 宏到底有什么魔法?而 SwiftData 又是如何确保 Actor 的执行序列与 ModelContext 使用的串行队列保持一致呢?
通过在 Xcode 中展开 ModelActor 宏,我们可以看到生成的完整代码:
actor DataHandler {
nonisolated let modelExecutor: any SwiftData.ModelExecutor
nonisolated let modelContainer: SwiftData.ModelContainer
init(modelContainer: SwiftData.ModelContainer) {
let modelContext = ModelContext(modelContainer)
modelExecutor = DefaultSerialModelExecutor(modelContext: modelContext)
self.modelContainer = modelContainer
}
}
extension DataHandler: SwiftData.ModelActor {}
// The code below is not generated by ModelActor
public protocol ModelActor : Actor {
/// The ModelContainer for the ModelActor
/// The container that manages the app’s schema and model storage configuration
nonisolated var modelContainer: ModelContainer { get }
/// The executor that coordinates access to the model actor.
///
/// - Important: Don't use the executor to access the model context. Instead, use the
/// ``context`` property.
nonisolated var modelExecutor: ModelExecutor { get }
/// The optimized, unonwned reference to the model actor's executor.
nonisolated public var unownedExecutor: UnownedSerialExecutor { get }
/// The context that serializes any code running on the model actor.
public var modelContext: ModelContext { get }
/// Returns the model for the specified identifier, downcast to the appropriate class.
public subscript<T>(id: PersistentIdentifier, as as: T.Type) -> T? where T : PersistentModel { get }
}通过代码可以看出,在构造过程中主要会进行两个操作:
- 使用传入的 ModelContainer 创建一个 ModelContext 实例。
构造方法运行在哪个线程,决定了创建的 ModelContext 所采用的串行队列,从而也影响了 Actor 的执行队列。
- 根据新创建的 ModelContext,创建一个 DefaultSerialModelExecutor(自定义的 Actor 执行者)。
DefaultSerialModelExecutor 是 SwiftData 声明的 Actor 执行者。它的主要职责是将传入的 ModelContext 实例使用的串行队列作为当前 Actor 实例的执行队列。
为了判断 DefaultSerialModelExecutor 的作用是否和我们预期的一样,我们可以通过下面的代码进行验证:
import SwiftDataKit
actor DataHandler {
nonisolated let modelExecutor: any SwiftData.ModelExecutor
nonisolated let modelContainer: SwiftData.ModelContainer
init(modelContainer: SwiftData.ModelContainer) {
let modelContext = ModelContext(modelContainer)
modelExecutor = DefaultSerialModelExecutor(modelContext: modelContext)
self.modelContainer = modelContainer
}
func checkQueueInfo() {
// Get Actor run queue label
let actorQueueLabel = DispatchQueue.currentLabel
print("Actor queue:",actorQueueLabel)
modelContext.managedObjectContext?.perform {
// Get context queue label
let contextQueueLabel = DispatchQueue.currentLabel
print("Context queue:",contextQueueLabel)
}
}
}
extension DataHandler: SwiftData.ModelActor {}
// get current dispatch queue label
extension DispatchQueue {
static var currentLabel: String {
return String(validatingUTF8: __dispatch_queue_get_label(nil)) ?? "unknown"
}
}SwiftDataKit 将让开发者能够访问 SwiftData 元素底层的 Core Data 对象。
在 checkQueueInfo 方法中,我们分别获取并打印了当前 actor 的执行序列和托管对象上下文对应的队列的名称。
Task.detached {
// create handler in non-main thread
let handler = DataHandler(modelContainer: container)
await handler.checkQueueInfo()
}
// Output
Actor queue: NSManagedObjectContext 0x600003903b50
Context queue: NSManagedObjectContext 0x600003903b50当在非主线程上创建 DataHandler 实例时,托管对象上下文将创建一个名为 NSManagedObjectContext + 地址的私有串行队列,Actor 的执行队列与其一致。
Task { @MainActor in
// create handler in main thread
let handler = DataHandler(modelContainer: container)
await handler.checkQueueInfo()
}
// Output
Actor queue: com.apple.main-thread
Context queue: com.apple.main-thread在主线程上创建 DataHandler 实例时,托管对象上下文和 Actor 均为主线程队列。
根据输出可以看到,Actor 的执行队列与上下文所使用的队列完全一致,证实了我们之前的猜测。
SwiftData 通过使用 Actor 来确保操作在正确的队列上运行,这也可以给 Core Data 开发者提供启示。可以考虑在 Core Data 中通过自定义的 Actor 执行者来实现类似的功能。
通过 PersistentIdentifier 获取数据
在 Core Data 的并发编程中,除了要在正确的队列上进行操作外,另一个重要的原则是不要在上下文之间传递 NSManagedObject 实例。这个规则同样适用于 SwiftData。
如果想在另一个 ModelContext 中对某个 PersistentModel 对应的存储数据进行操作,可以通过传递该对象的 PersistentIdentifier 来解决。PersistentIdentifier 可以被视为 NSManagedObjectId 的 SwiftData 实现。
下面的代码将尝试通过传递进来的 PersistentIdentifier 获取对应的数据并进行修改:
extension DataHandler {
func updateItem(identifier: PersistentIdentifier, timestamp: Date) throws {
guard let item = self[identifier, as: Item.self] else {
throw MyError.objectNotExist
}
item.timestamp = timestamp
try modelContext.save()
}
}
let handler = DataHandler(container:container)
try await handler.updateItem(identifier: item.id, timestamp: .now )在代码中,我们使用了一个 ModelActor 协议提供的下标方法。该方法首先尝试从当前 actor 持有的 ModelContext 中查找是否有对应的 PersistentModel。如果没有的话,它将尝试从行缓存以及持久化存储中获取。可以将其视为 Core Data NSManagedObjectContext 的 existingObject(with:) 方法的对应版本。有趣的是,这个直接穿透到持久化存储的方法只在 ModelActor 协议中提供了实现。从这个角度来看,SwiftData 的开发团队也在有意识地引导开发者使用这种( ModelActor )数据操作逻辑。
另外,ModelContext 还提供了两种通过 PersistentIdentifier 获取 PersistentModel 的方法。registeredModel(for:) 对应于 NSManagedObjectContext 的 registeredObject(for:) 方法;model(for:) 对应于 NSManagedObjectContext 的 object(with:) 方法。
func updateItemInContext(identifier: PersistentIdentifier, timestamp: Date) throws {
guard let item = modelContext.registeredModel(for: identifier) as Item? else {
throw MyError.objectNotInContext
}
item.timestamp = timestamp
try modelContext.save()
}
func updateItemInContextAndRowCache(identifier: PersistentIdentifier,timestamp: Date) throws {
if let item = modelContext.model(for: identifier) as? Item {
item.timestamp = timestamp
try modelContext.save()
}
}这三种方式的区别如下:
existingObject(with:)
如果上下文识别到了指定的对象,该方法会返回该对象。否则,上下文会从持久化存储中获取并返回一个完全实例化的对象。与 object(with:) 方法不同,该方法永远不会返回一个惰值状态的对象。如果对象既不在上下文中,也不在持久化存储中,该方法会抛出一个错误。简单来说,除非该数据在持久化存储上并不存在,否则必然会返回一个非惰值状态的对象。
registeredModel(for:)
此方法只能返回在当前上下文中已注册的对象(标识符相同)。如果找不到,则返回 nil。当返回值为 nil 时,并不表示该对象一定不存在于持久化存储中,只表示该对象未在当前上下文中注册。
model(for:)
即使对象没有在当前上下文中注册,该方法仍会返回一个空的惰值对象——一个占位对象。当用户实际访问该占位对象时,上下文将尝试从持久化存储中获取数据。如果数据不存在,可能会导致应用崩溃。
第二道防线
并非每个开发者都会严格按照 SwiftData 所期望的方式(ModelActor)进行并发编程。在代码逐步复杂后,或许会不小心出现访问或设置其他队列上的 PerisistentModel 属性的情况。根据 Core Data 的经验,在开启调试参数 com.apple.CoreData.ConcurrencyDebug 1 的情况下,这种访问将必然导致应用崩溃。
更多调试参数,请阅读 Core Data with CloudKit(四)—— 调试、测试、迁移及其他 一文。
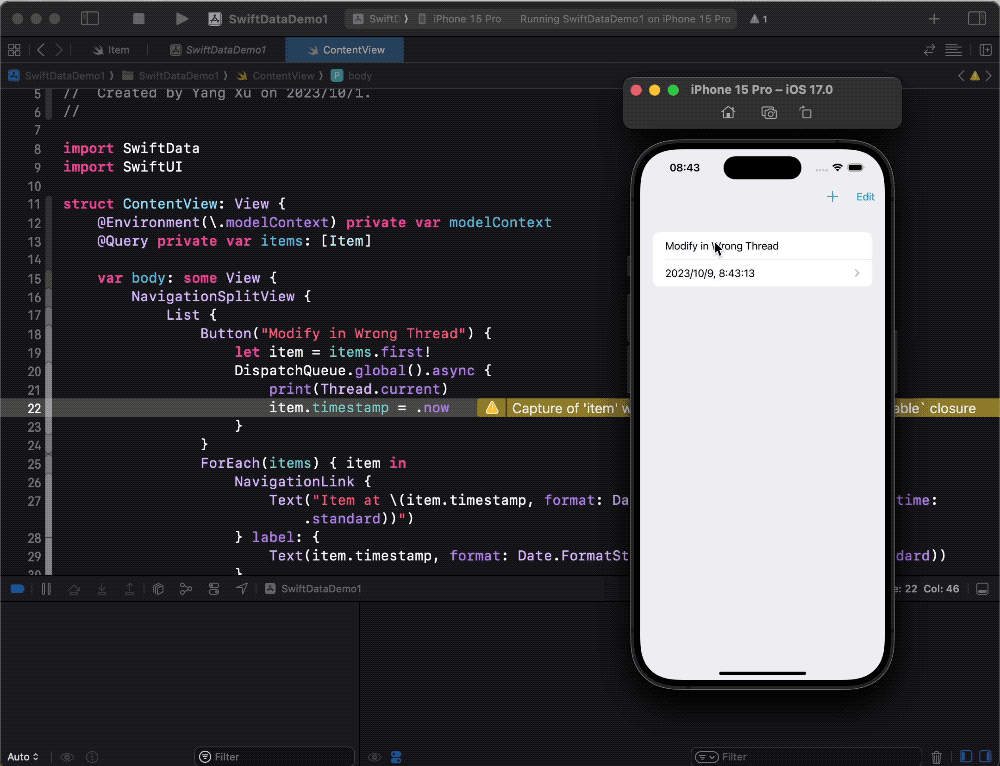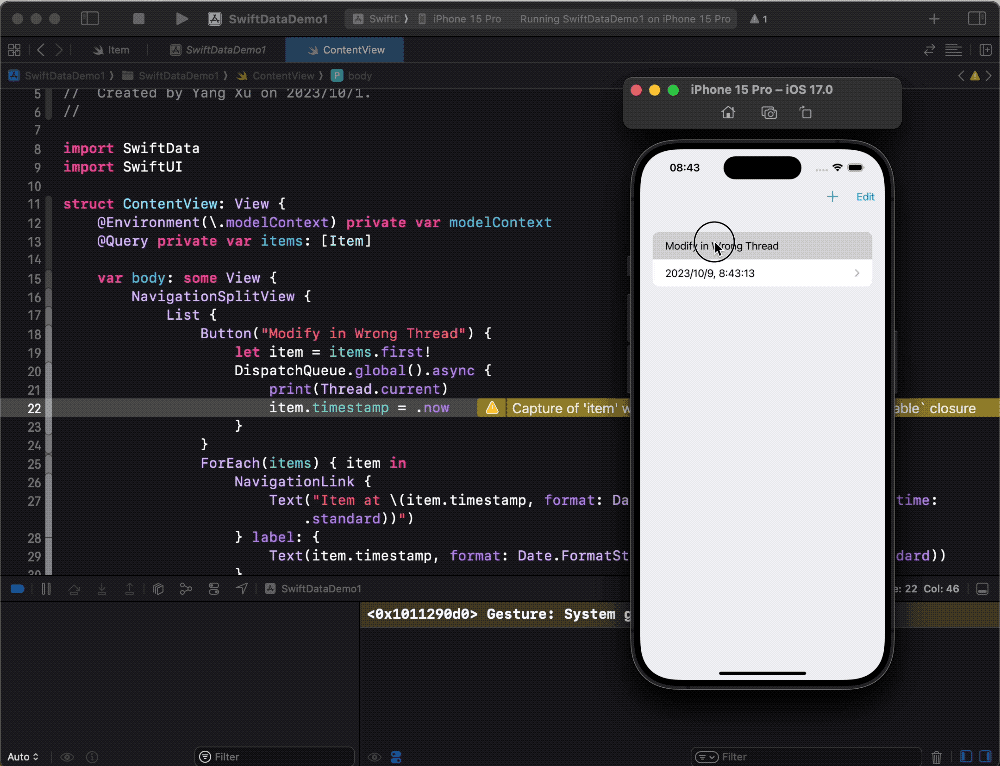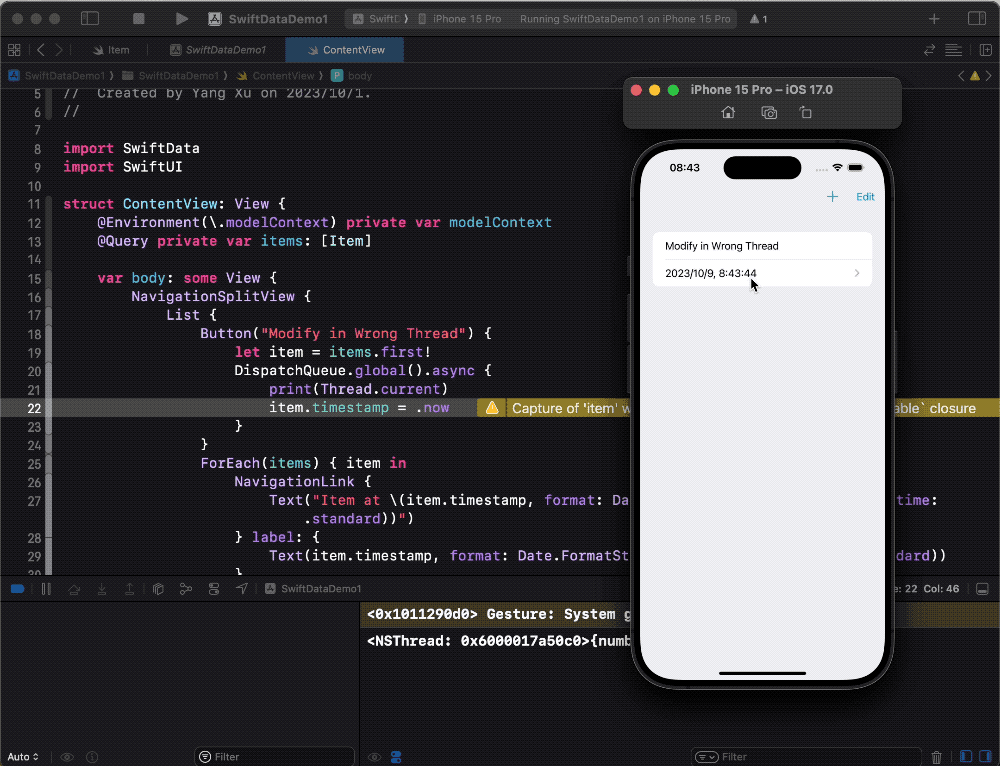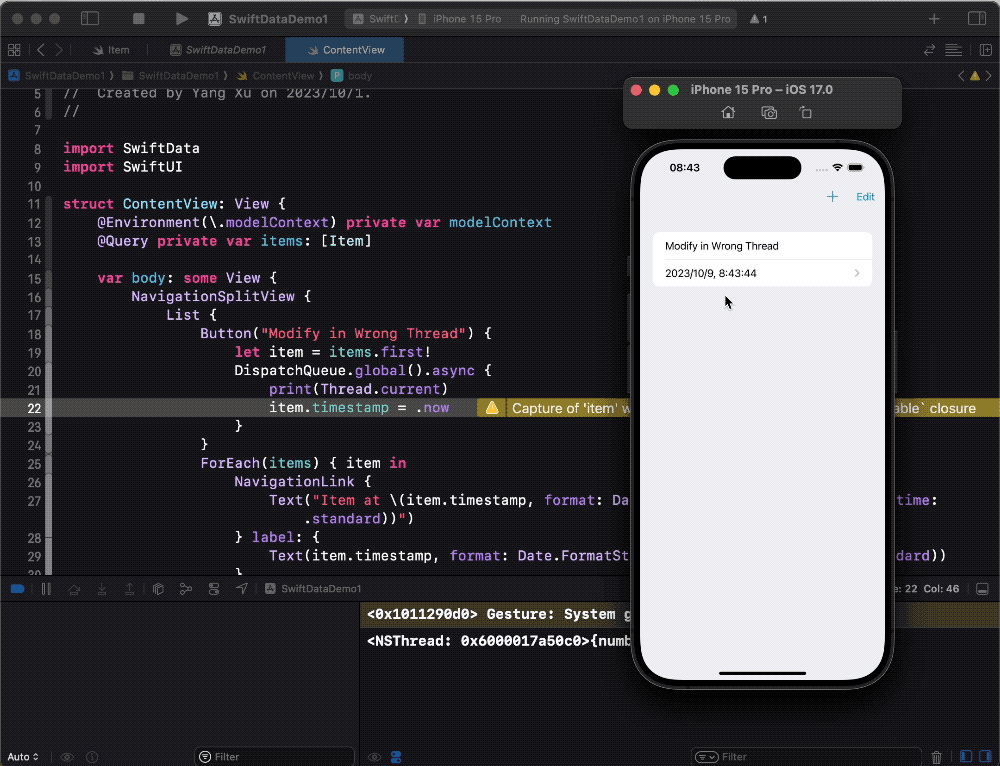
但是,在 SwiftData 中,尽管我们会收到一些警告信息(Capture non-sendable),上述操作并不会出现问题,可以正常进行数据访问和修改。这是为什么呢?
下面的代码将在一个非主线程中修改主线程上的 Item 对象属性。点击按钮后,属性修改成功。
Button("Modify in Wrong Thread") {
let item = items.first!
DispatchQueue.global().async {
print(Thread.current)
item.timestamp = .now
}
}
如果你看过上一篇文章 揭秘 SwiftData 的数据建模原理,或许会记得其中提到 SwiftData 为 PersistentModel 和 BackingData 提供的 Get 和 Set 方法不仅可以读取和设置属性,还具备队列调度的能力(确保线程安全)。换句话说,即使我们在错误的线程(队列)对属性进行修改,这些方法会自动将操作切换到正确的队列中进行。通过进一步尝试,我们发现这种调度能力至少存在于 BackingData 协议的实现层面。
Button("Modify in Wrong Thread") {
let item = items.first!
DispatchQueue.global().async {
item.persistentBackingData.setValue(forKey: \.timestamp, to: Date.now)
}
}本节内容并非鼓励大家绕过 ModelActor 的方式进行数据操作,但通过这些细节,我们可以看出 SwiftData 团队为了避免出现线程安全问题而做出了很多努力。
总结
或许有人会和我一样,在了解了 SwiftData 新的并发编程方式后,在欣喜之余会有一种说不出来的感觉。经过了一段时间的思考,我似乎找到了这种异样感觉的原因 —— 代码风格。显然,之前在 Core Data 中常用的数据处理逻辑并不完全适用于 SwiftData。那么如何写出更具备 SwiftData 味道的代码呢?如何让数据处理代码与 SwiftUI 更加契合?这是我们今后要研究的课题。